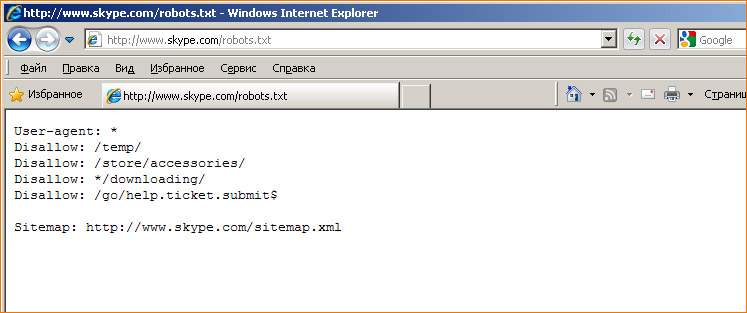
– запрещает скачивать весь сайт
Спецсимволы в robots.txt
При указании путей директив Allow-Disallow можно использовать
спецсимволы '*' и '$', задавая, определенные регулярные выражения.
Символ ‘#’ отделяет комментарии к коду в файле robots.txt.
Спецсимвол '*' означает любую (в том числе пустую) последовательность символов. Примеры:
User-agent: Yandex
Disallow: /cgi-bin/*.aspx # запрещает '/cgi-bin/example.aspx' и '/cgi-bin/private/test.aspx'
Disallow: /*private # запрещает не только '/private', но и '/cgi-bin/private'
По умолчанию к концу каждого правила, описанного в robots.txt, приписывается '*', например:
User-agent: Yandex
Disallow: /cgi-bin* # блокирует доступ к страницам начинающимся с '/cgi-bin' Disallow: /cgi-bin # то же самое
Чтобы отменить '*' на конце правила, можно использовать спецсимвол '$', например:
User-agent: Yandex
Disallow: /example$ # запрещает '/example', но не запрещает '/example.html'
User-agent: Yandex
Disallow: /example # запрещает и '/example', и '/example.html'
User-agent: Yandex
Disallow: /example$ # запрещает только '/example'
Disallow: /example*$ # так же, как 'Disallow: /example' запрещает и /example.html и /example
Как видно из примеров, директивы можно сочетать друг с другом. Как
правило, этого небольшого функционала достаточно для решения большинства
вопросов с индексированием сайта, остальные директивы нуждаются в
уточнении в рамках работы конкретной поисковой системы. Популярные
поисковики предоставляют вебмастерам cправочную информацию по
особенностям работы своих поисковых роботов – например, «
Яндекс» и «
Google».
Безопасность сайта и robots.txt
Поисковые роботы не могут добраться до страниц, доступ к которым
возможен исключительно после авторизации, то есть с помощью
обязательного ввода пароля. Это могут быть не только профили
пользователей сайта, но и аккаунты администраторов. Таким образом,
включать эти страницы в robots.txt не имеет смысла.
Будет разумно указать поисковым роботам не включать в индекс страницы с
формой авторизации для пользователей сайта. Если же для администраторов
сайта есть отдельная страница авторизации, на которую нельзя перейти с
главной или внутренних страниц сайта, и эта страница имеет нестандартный
вид URL, то сомнительно включать её в robots.txt под директивой
Disallow. Помните о том, что опытный вебмастер всегда сможет обнаружить
стандартную страницу авторизации для популярных CMS, а в индекс системы
могут попасть страницы, ссылки на которых есть на уже проиндексированных
страницах других сайтов.
Процитируем также страницы помощи Google
о поисковом роботе Googlebot:
«Хотя Google не сканирует и не индексирует содержание страниц, заблокированных в файле robots.txt, URL-адреса, обнаруженные на других страницах в Интернете, по-прежнему могут добавляться в индекс. В результате URL страницы, а также другие общедоступные сведения, например текст ссылок на сайт или заголовок из каталога Open Directory Project, могут появиться в результатах поиска Google».
Таким образом, хотя в индекс поисковой системы может не попасть
содержимое страниц, могут попасть их URL, что, в общем-то, не является
гарантией того, что конфиденциальные данные не попадут в руки
злоумшыленников.
SEO-специалист должен составить список страниц, которые совершенно точно
не должны попасть в открытый доступ в интернете, однако поскольку
список этих страниц будет находиться в открытом для всех файле
robots.txt, злоумышленникам не придётся даже искать страницы с «той
самой» секретной информацией, о чём прямо сказано на сайте
robotstxt.org: «Файл robots.txt виден всем. Не пытайтесь использовать
этот файл для того, чтобы спрятать информацию».
Кроме того, не все роботы соблюдают общепринятые стандарты для
robots.txt. А также robots.txt может использоваться специально
написанными программами, цель которых – поиск уязвимостей ваших
веб-серверов.
Эти вещи всегда нужно иметь в виду, если вы заботитесь о безопасности данных на вашем сайте.
Использование robots.txt в мошеннических целях
Файл robots.txt можно использовать и с целью нанести ущерб сайту. Всегда
будьте в курсе того, кто имеет доступ к вашему сайту. С помощью
robots.txt можно добиться понижения позиций сайта вплоть до полного
выпадения его из индекса. Приведём некоторые примеры таких манипуляций.
- Директива
Disallow может использоваться для запрета индексирования отдельных
папок (разделов сайта). Обратите внимание на имена этих папок: кроме
разделов со служебной информацией там могут оказаться и разделы с
контентом.
- Директива
Crawl-delay отвечает за временной промежуток в секундах между
последовательной загрузкой страниц сайта и используется при больших
нагрузках на вебсервер. Увеличение временного промежутка может привести к
тому, что поисковый робот будет индексировать сайт слишком долго.
Как мы говорили в самом начале нашей рассылки, такие манипуляции с
robots.txt легко определить даже не вникая в структуру сайта – просто
открыв файл robots.txt в браузере.
Noindex, nofollow
В связи с файлом robots.txt нельзя не упомянуть микроформаты noindex и nofollow.
Значение nofollow атрибута rel тега <a> (запрет передачи веса по
ссылке) входит в спецификацию HTML, и на данный момент соблюдается всеми
популярными поисковыми системами.
Тег noindex был предложен компанией «Яндекс». Этот парный тег
предназначен для запрета индексирования части содержимого на странице,
например так:
...
<noindex>Текст или код, который нужно исключить из индексации Яндекс</noindex>
...
На данный момент тег noindex используется только Яндексом. Более того,
поскольку тег noindex не входит в официальную спецификацию языка HTML,
то большинство HTML-валидаторов считает его ошибкой. Потому для того,
чтобы сделать код с noindex валидным рекомендуется использовать тот
факт, что noindex не чувствителен к вложенности и это позволяет
использовать следующую конструкцию:
<!--noindex-->Текст или код, который нужно исключить из индексации Яндекс<!--/noindex-->
Возможно использование noindex в качестве мета-тега на конкретной странице (например, /page.html):
<html>
<head>
<meta name="robots" content="noindex" />
<title>Эта страница не будет проиндексирована</title>
</head>
...
Приведённая выше запись аналогична следующей конструкции в robots.txt:
User-agent: Yandex
Disallow: /page.html
Что делать, если конфиденциальные данные с вашего сайта попали в открытый доступ
К сожалению, бывают неприятные ситуации, когда не все страницы с
конфиденциальными данными были закрыты от индексации. Рано или поздно
такие страницы попадают в сеть и распространяются по интернету, вызывая
многочисленные скандалы, шумиху и нередко – судебные иски. Вебмастерам в
этом случае следует придерживаться следующего порядка действий:
- Определите
список страниц, которые необходимо закрыть от индексации. Выясните
причину их попадания в открытый доступ: если эти страницы должны быть
доступны только через форму авторизации, примите соответствующие меры в
модулях вашей CMS.
- Добавьте
список страниц в файл robots.txt с помощью директивы Disallow для всех
поисковых роботов. Помните, что если информация появилась в индексе
одной поисковой системе, то в течение короткого времени она появится в
индексе как минимум всех популярных поисковых систем, а также может быть
сохранена пользователями интернета.
- Обратитесь напрямую в поисковые системы для скорейшего удаления страниц из индекса, соответствующие формы есть у «Яндекса» и у «Google».
- Узнайте,
была ли скопирована конфиденциальная информация с вашего сайта и
выложена на сторонних ресурсах. Если это произошло, обратитесь к
владельцам сайтов (модераторам) с просьбой об удалении контента. Вы
также можете обратиться в техподдержку поисковых систем.
К сожалению, ответственность за распространение конфиденциальных данных
лежит в первую очередь на плечах владельца сайта – источника утечки.
Выводы
Итак, сделаем некоторые основополагающие выводы об использовании файла robots.txt.- Robots.txt нельзя использовать с целью скрыть какую-либо информацию: указывая страницы, которые следует игнорировать поисковым машинам, вы в любом случае сами сообщаете место, где на вашем сайте могут содержаться конфиденциальные данные.
- Не все поисковые роботы (не считая программ злоумышленников) соблюдают общепринятые стандарты, некоторые роботы имеют свои особенности. Занимаясь поисковой оптимизацией, SEO-специалист должен в первую очередь ориентироваться на все те поисковые системы, с которых на сайт приходит существенное количество трафика.
- Проектируйте свой сайт таким образом, чтобы свести использование robots.txt (и в особенности директивы Disallow) к минимуму. О безопасности информации следует подумать на самых ранних этапах создания сайта, чтобы впоследствии не пришлось «латать дыры».
- Если вы столкнулись с проблемой утечки данных со своего сайта в открытый доступ, немедленно запретите поисковым системам индексацию страниц с конфиденциальной информацией, а затем обратитесь в поисковую систему, чтобы максимально быстро исключить страницы из поиска.
- Размещайте ваши сайты на хорошем хостинге и не перегружайте страницы информацией, чтобы не пришлось указывать поисковым роботам технические указания о времени обхода страниц.
Заметим, что механизмы поисковых систем стремятся к такой организации, чтобы создать сайт было максимально просто, а вебмастерам не приходилось изучать особенности работы поисковых роботов. Тем не менее, на данный момент знать основы использования robots.txt принципиально важно при продвижении в первую очередь интернет-магазинов и других сайтов, содержащих конфиденциальную информацию, а также при смене структуры сайта или переезде сайта на новый домен.